What I Learned Writing My Own CloudKit Syncing Library
Last week, I published CloudSyncSession, a Swift library that builds on top of the CloudKit framework to make it easier to write sync-enabled, offline-capable apps.
I started CloudSyncSession over two years ago with the goal of replicating NSPersistentCloudKitContainer's syncing behavior, without the Core Data hard dependency. Additionally, I wanted a solution that provided harder guarantees, more control, and more diagnostic information. I didn't find an existing solution that met all of my requirements, so I (reluctantly) set out to build my own.
After years of refining this framework and fixing various bugs in my app, I've learned a lot about CloudKit syncing. You can glean some of my learnings by reading the code, but there's a lot more that I felt I could share with a proper, technical blog post.
So here it is: the blog post I wish had existed before starting CloudSyncSession.
Key Concepts
If you are using CloudKit to synchronize all data between multiple offline-capable clients, it's really important to understand these core concepts. You can learn and read about these in the official CloudKit documentation and from WWDC videos, but I figured I'd offer brief explanations in my own words.
Records
Records are the atomic unit of CloudKit syncing. They represent a single, syncable item. Each record has a universal identifier, the record ID, which is composed of the record name and the associated zone. You can't have two records with the same record ID in the same zone.
Zones and Change Tokens
Zones are a collection of records. You can query for records in a zone in a variety of ways.
For offline-capable apps where the objective is to mirror all data across clients, you'll want to take advantage of a key property of zones: that they track all additions and deletions of records. This capability works using change tokens, which are opaque unique identifiers that point to a specific change in the zone.
With a change token, you can query for all changes since the change that the token represents (see CKFetchRecordZoneChangesOperation). It's a paginated API, so the change token you supply will be nil for the first sync. A successful zone changes query response will include a list of new records, deleted record IDs, and a new change token you can use for your next query.
Change Tags
Records contain various metadata that is managed directly by the CloudKit framework. The most critical piece of metadata is the record's change tag.
Change tags are a critical component to how CloudKit handles conflicts. Change tags are updated whenever a record gets updated. When a client attempts to modify a record, the CloudKit server checks to see if the change tag matches the latest known version on the server. If the change tag is older or unknown, CloudKit treats this as a conflict and signals back to the client that this record needs a resolution.
Subscriptions
Subscriptions are required to register for cloud-originated notifications whenever there is a change in the associated zone. You can use these notifications to know when to trigger a fetch, which is necessary to create a near-realtime user experience.
How To Avoid and Handle Errors
CloudKit can be quite fussy. If you want to build a good user experience, you'll need to play by its rules, including ones that aren't explicitly documented.
Split Up Work
When forming a modify operation, you should limit the number of new and deleted records to 400 (suggested value from CKError.Code.limitedExceeded documentation). In CloudSyncSession, work is automatically split up in chunks of 400.
There are many types of CloudKit errors to handle (see CKError codes). One is limitExceeded. When you see this error, you should retry after splitting up the work into smaller chunks. In CloudSyncSession, these errors are handled by splitting up the work into halves.
Dedupe Records
When forming a modify operation, always dedupe records by record ID. CloudKit errors if you request modifying a record and deleting it in the same operation, so don't include record IDs to be deleted in the list of records to be saved.
Queue Up Work
CloudKit doesn't like being asked to do too much at one time. I found the best results when just having one single operation in flight at a time. Not only does this lead to fewer CloudKit throttling errors, it makes processing more predictable and eliminates many classes of errors.
CloudSyncSession will do this for you, but it won't dedupe records across multiple modification operations. For this reason, I recommend managing a separate queue that is external to CloudSyncSession. Defer issuing modify requests until the session is not busy with an existing one. Try to use the latest copy of the record with the most recent record change tags to avoid conflicts.
It also doesn't benefit you to issue concurrent fetch requests. Once a fetch request has completed, you can issue another one after some fixed interval, e.g. 30 seconds, or when the app receives a subscription notification.
Treat Catastrophic Errors Differently than Transient Ones
A catastrophic error indicates something has majorly gone wrong, and it'd be better to just stop everything altogether than continue. For example, a badDatabase or notAuthenticated are not easily recoverable and require special user interaction.
CloudSyncSession checks for these errors and halts. It is the responsibility of the app to listen for when the session becomes halted, and to handle the error in some way. For example, it could show an error state and alert the user.
For catastrophic errors, it's best to suspend work and avoid issuing requests that would make CloudKit start to throttle the client.
Retry Transient Errors With a Backoff Strategy
Transient errors, like errors due a network disruption or record conflict, can and should be retried.
When retrying, you should use the userInfo[CKErrorRetryAfterKey] field on the CKError to determine how long to wait before issuing the retried operation. If that field doesn't exist, I recommend using an exponential backoff based on the number of retries. I'd also consider limiting the number of possible retries, to avoid continuously hitting CloudKit with a failing operation.
Respond to Being Rate Limited
CloudKit implements rate limiting. It has a special CKError code for this, requestRateLimited, but I've actually never seen an error with this code. In practice, rate limiting is indicated by serviceUnavailable (CKError 6, HTTP code 503). I was thrown off by this for a while, because I wouldn't expect to see a 503 code being used for rate limiting.
I issued a feedback to Apple about how this is unexpected and confusing. They replied with a reasonable explanation:
From the description, it sounds like you're hitting our throttling by sending too many requests too quickly.
You're right that a 4xx code would be more appropriate for rate limiting, but we use 503 for historical reasons and can’t make a switch easily.
In CloudSyncSession, I do not issue concurrent operations and I wait a minimum duration of 2 seconds between when one operation ends and another begins. If there is ever a failure of any kind, I exponentially increase the throttle duration. Then after a successful request, I decrease the throttle by 33%. You don't want to decrease the throttle too quickly, as I've found this leads to rate limit thrashing.
Avoid Spamming Bad Requests
CloudKit also does not like it when you make a lot of bad requests that result in errors in a short period of time.
For example, if you submit modify operations where most or all of the records contain outdated or missing change tags, CloudKit will start to aggressively rate limit that client. The rate limiting can last a long time – I've seen it last up to several hours.
Sometimes You Just Have to Try Again Later
Even after implementing all of these mitigations and error handling logic, you'll still encounter random, inexplicable errors. Even the CloudKit framework daemon can just crash on you or fail to respond. In my app, FoodNoms, I check the status of the CloudSyncSession state whenever the app moves into the foreground. If it has halted due to a catastrophic error or after failing to retry an operation, I restart the session.
Avoid Data Discrepancies By Diligently Tracking Work
When mirroring data across clients, you want to try your hardest to avoid data discrepancies. Users never want to see data missing from one device.
Only commit change tokens after you've successfully saved fetched records to disk. Write your processing code to be idempotent, so that if there is a failure, there's no harm in re-fetching the same data.
You'll need some mechanism to keep track of what records need to be saved to CloudKit via modification operations. However you do this, you'll want it to be resilient. Only consider work done after the operation succeeds. If the app gets unexpectedly terminated, you should retry the same exact set of work on the next launch. My app accomplishes this with a persistent queue with a checkpoint pointer that points to the last record that has been successfully saved to CloudKit.
Conflict Resolution
When resolving a conflict, you'll want to implement logic that is appropriate for your app and record types.
Figuring out the best conflict resolution algorithm for your app can be tricky. You'll need to consider at what level you need to guarantee consistency. Record level or field level? Also consider the relationships between records. Are there causal/temporal relationships between different records? What realistic usage patterns do you expect to see? How many concurrent devices? How likely is it that one device would be disconnected or out of sync for an extended period of time? How likely are records to be modified at all? Are record modifications even required, or can all records be considered immutable?
There are many strategies you can consider, but allow me to talk about the tradeoffs of a few common, simple ones:
A popular, simple strategy is "last writer wins". You can implement this by comparing the server modificationDate values of the records, which represents the date that the server last saved that copy of the record (corresponding to the change tag). However, this could lead to trouble when queuing changes locally. Here's an example scenario: the user makes changes to a record in quick succession – not quick enough to be deduped, but quick enough so that both copies are queued up. The desired behavior is that the second edit should be the one that wins. Instead, what happens is this:
- Both edits are queued up using the same record change tag and modification dates.
- The first edit to the record is successfully saved in the cloud.
- The second edit results in a conflict, as CloudKit detects it contains an outdated change tag.
- The conflict resolver then sees that the server copy has a newer modification date. Since this is the "last writer", it "wins" the resolution.
You can use a local "last writer wins" strategy, where instead of the CloudKit modification date field, you manage a local field. However, you are opening yourself up to bad resolutions when multiple clients have unsynchronized clocks.
A third simple strategy, one that I'm using today with FoodNoms, is to keep track of the edit count on each record. Each time a record is edited, that counter is incremented. Then in the conflict resolver, the record that has the higher edit count is the winner. This is a very rudimentary strategy, but it works well enough for a single-user app like FoodNoms.
One important thing to note: after handling your conflicts, you will want to re-issue a modification operation with records that have the change tags that match the server's.
Schema Design
Record IDs
First off, consider your strategy for record IDs. Consider using globally unique identifiers, like UUIDs, that can easily allow you to dedupe and guarantee uniqueness locally.
References
I have found that record references aren't that useful for use cases where the end goal is to mirror all data across clients. Instead, you can record foreign keys as plain record fields, which the client can use to perform join operations.
Versioning
Consider your versioning strategy. CloudKit schemas can be evolved in a forward-compatible manner, i.e. you can add new fields but not delete or change existing ones. Given this, in your client code, treat as many fields as optional, if possible. In the future, you may not want to use those fields any more.
Consider a version field that indicates the semantic version that a particular record instance represents. With this field, you can check if a record's version is from a future version of the app, in which case you likely want to halt all CloudKit syncing and prompt the user to upgrade to the latest version of the app. You can also check to see if the record contains any unknown keys, in which case you will also likely want to do the same. You can also use this field to do client-level migrations or fixups from older versions, if necessary.
Encrypted Values
Encrypted record fields are super simple to use. Instead of record["foo"] you use record.encryptedValues["foo"]. The caveat with encrypted fields is it precludes you from adding server-side indexes on that field. However, if you're only targeting apps that will work offline and mirror all data from the cloud, this isn't that big of a deal. A compromised solution is to encrypt some, not all, fields. For example, you could choose to only encrypt fields that are sensitive and would likely never be used as a filter in a record fetch operation.
Other Tips
How to Delete All Data from a Zone
Deleting all user data in iCloud from the app is easy and straightforward. Simply request to delete the zone using CKModifyRecordZonesOperation. After doing so, make sure to disable syncing and reset all record change tags, otherwise the app will bombard CloudKit with records that will all be treated as conflicts, which will undoubtedly lead to severe rate limiting.
How to Develop Against the Production Environment
Set com.apple.developer.icloud-container-environment to Production in your app's entitlements file.
Keep Track of Deleted Records
Users never expect deleted data to reappear. You might need special handling to make sure this never happens.
It's possible to enter a condition where your app submits a modification request to create or edit a record, then a deletion request for that same record afterwards. Depending on network latencies and how these operations are queued up, your app might start processing the first request's successful response before the deletion request finishes. You'll want to account for this and skip re-saving any records that have been known by the client to have been deleted. FoodNoms handles this by maintaining a local database table that contains all previously-deleted record IDs.
Diagnostics Information Is Essential for a Good User and Support Experience
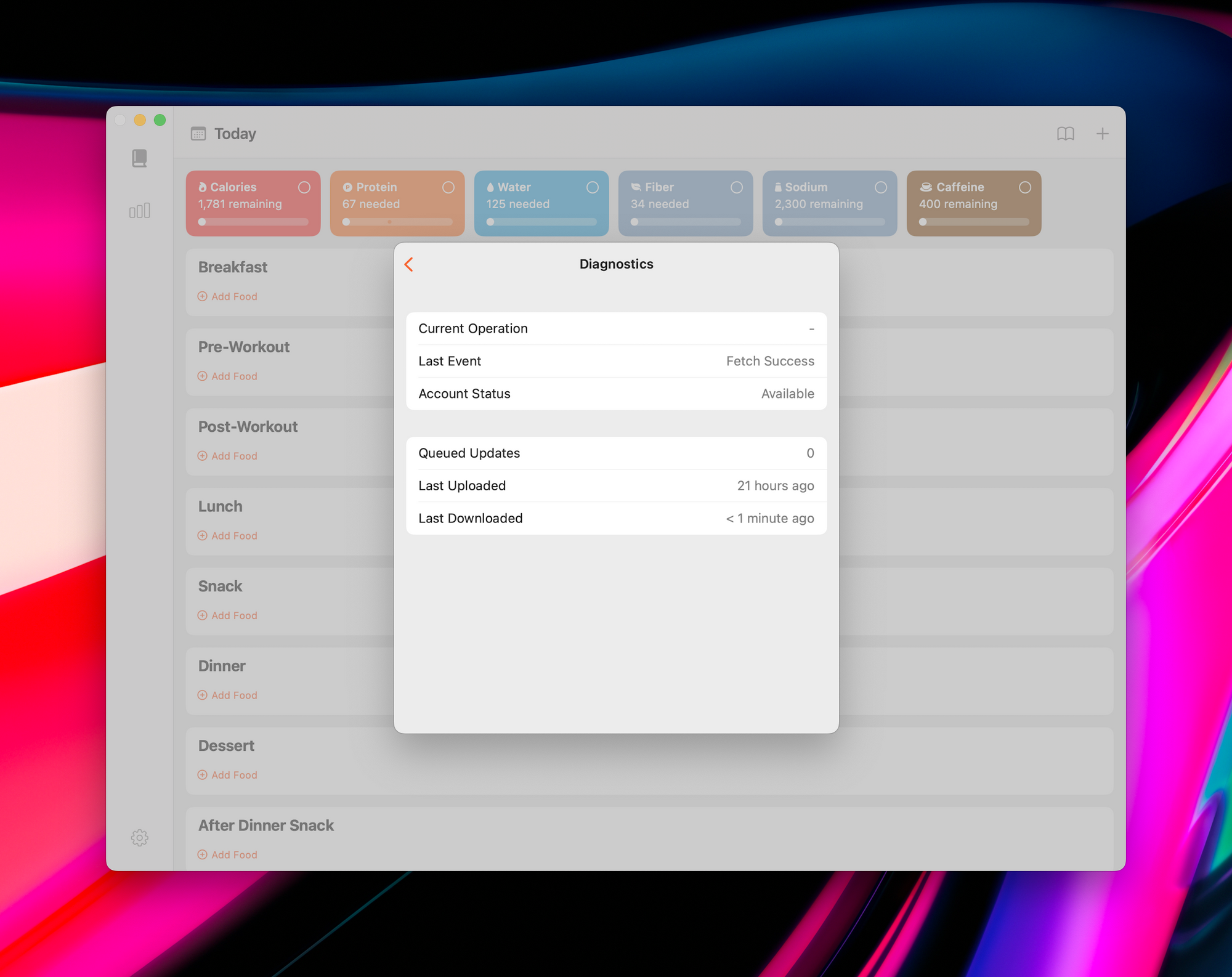
Users want to know if their data is being synced properly. And from a customer support perspective, it's invaluable to have logs and rich diagnostic information about the sync engine. Here are some diagnostics that I've found to be super helpful:
- How many records are queued up to be synced?
- How many records are saved locally that have change tags?
- When was the last time a fetch operation succeeded?
- When was the last time a modification operation succeeded?
- What's the CloudKit account status?
- Is there an operation in flight?
- What is the last operation that has been completed?
- What is the current throttle duration?
- Have we stopped syncing due to an error? If so, what's the error?
- If we are currently retrying an operation, how many times have we already retried it? What exactly is the error that led to the retry?
You can use a combination of these to distill a higher-level summary to the user, e.g. "Downloading…" or "Ready" or "Error". Then you can display a more in-depth display to the user and/or in diagnostic logs.
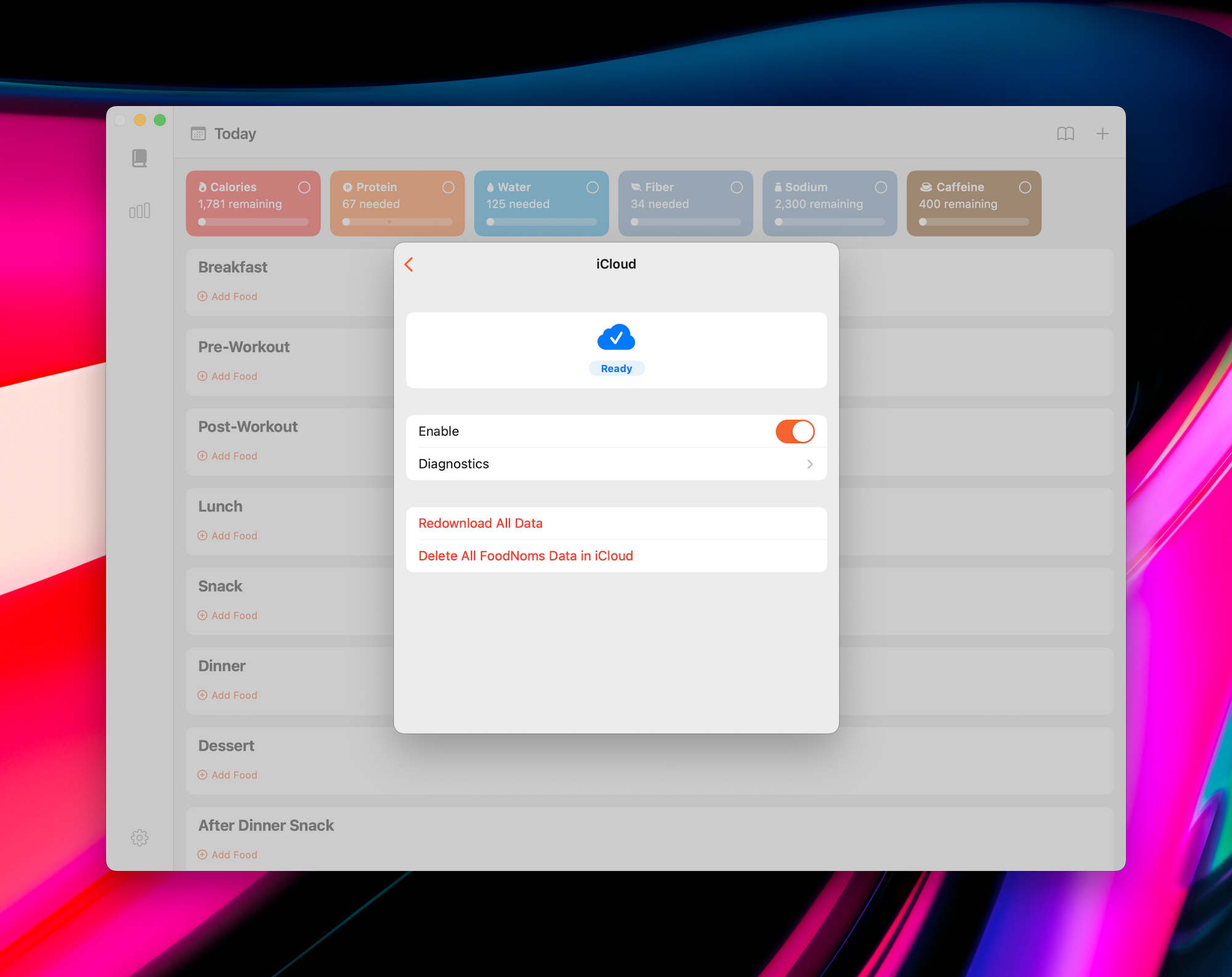
I hope this is helpful to others out there who are trying to learn CloudKit, build a CloudKit-based app, or perhaps have encountered some inexplicable CloudKit behavior. I tried to think of all the things that I wish I knew from the onset of starting CloudSyncSession.
I still think the best way to learn some of this stuff is by reading actual code. You can read the source code from CloudSyncSession and Cirrus on GitHub. Both libraries have a lot in common and generally aim to accomplish the same end goal, but take different approaches and offer different sets of tradeoffs.
If you have feedback to share with me, please message me on Mastodon.